Dużą optymalizację przeszedł także sam blok wykonawczy SM, w tym tzw. rdzenie CUDA. W stosunku do swojego poprzednika i wcześniejszych kart o zunifikowanych shaderach, każda pojedyncza jednostka obliczeniowa zawiera dwa osobne moduły odpowiedzialne za obliczenia stało- (integer arithmetic point) oraz zmiennoprzecinkowe (floating point unit).
Wcześniejsze układy NVIDII mogły pracować przy obliczeniach zmiennoprzecinkowych w standardzie IEEE 754-1985. W GF100 zaimplementowano nowy standard IEEE 754-2008, umożliwiający użycie instrukcji multiply-add (FMA – Fused Muliply-add) zarówno dla obliczeń o pojedynczej, jak i podwojonej precyzji. Instrukcje te pozwalają na jednoczesne wykonywanie operacji mnożenia i dodawania w jednym przejściu i w stosunku do MAD nie powodują obniżania precyzji wyniku.
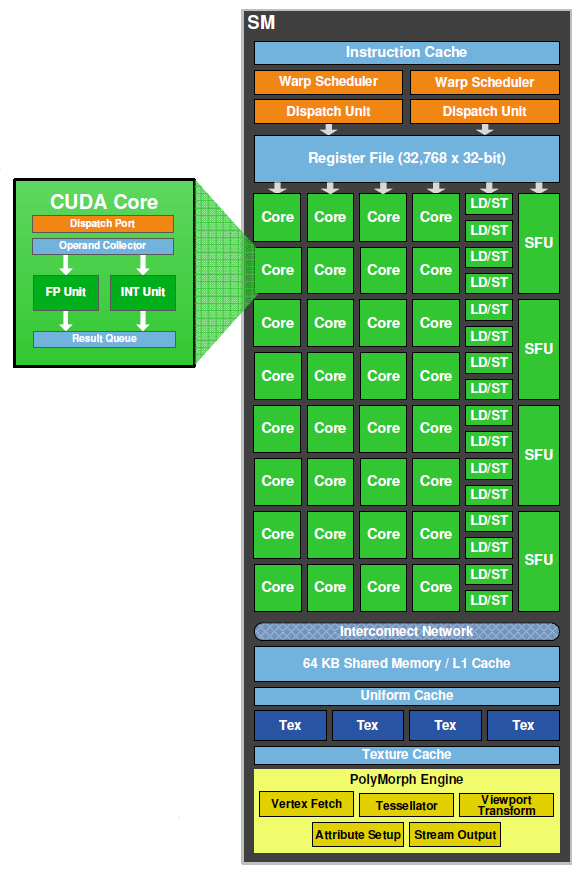
Schemat blokowy pojedynczego klastra SM
Jednostka stałoprzecinkowa podczas mnożenia nie jest już ograniczona jedynie do precyzji 24-bitowej. Od nowa zaprojektowane ALU obsługuje teraz pełną 32-bitową precyzję dla wszystkich instrukcji, zgodną z niemal każdym użytym standardem programowania. Jednostka została także zoptymalizowana pod kątem efektywniejszego wykonywania kodu o rozszerzonej (64-bitowej) dokładności.
Każdy z bloków SM ma do swojej dyspozycji po 16 jednostek Load i Store (ładowania i przechowywania). Przechowują one poszczególne adresy komórek danych umieszczonych w pamięci podręcznej L2 i pamięci graficznej DRAM. Konfiguracja jednostek LD/ST pozwala na jednoczesną adresację do 16 wątków na cykl zegarowy.
W skład struktury bloku SM wchodzą również 4 jednostki dla funkcji specjalnych - SFU (Special Function Unit), takich jak chociażby sinus, cosinus, pierwiastek czy odwrotność. Każda z nich jest w stanie wykonać pojedynczą instrukcję na wątek lub na cykl zegarowy. Potoki SFU zostały także oddzielone od dispatch procesora, dzięki czemu - pomimo zajętości - pozwalają w dalszym ciągu na komunikację rozdzielania wątków przez specjalizowany „junit”.
Jednym z większych usprawnień w stosunku do GT200 jest wydajność nowego układu w obliczeniach o podwojonej precyzji. Do 16 operacji mnożenia-dodawania, jakich jest w stanie wykonać jeden SM w GF100 (w jednym cyklu zegarowym), to ogromny skok jakościowy.
Rozkładem samych wątków zajmuje się specjalizowany, podwojony scheduler, w którego skład wchodzą po dwie jednostki warp oraz dispatch instruction. Podwojenie jednostek ma na celu efektywniejsze grupowanie i rozdzielanie wątków równolegle w grupach po 32. Grupy takie nazywane są warpami. Dwie niezależne jednostki pozwalają zatem na wykonywanie dwóch konkurencyjnych warpów w jednym czasie. Jedna instrukcja pochodząca z każdego wykonywanego w danym czasie warpa pozwala na przesłanie tejże instrukcji do każdego z 16 rdzeni CUDA, 16 LD/ST i 4 jednostek specjalnych SFU.
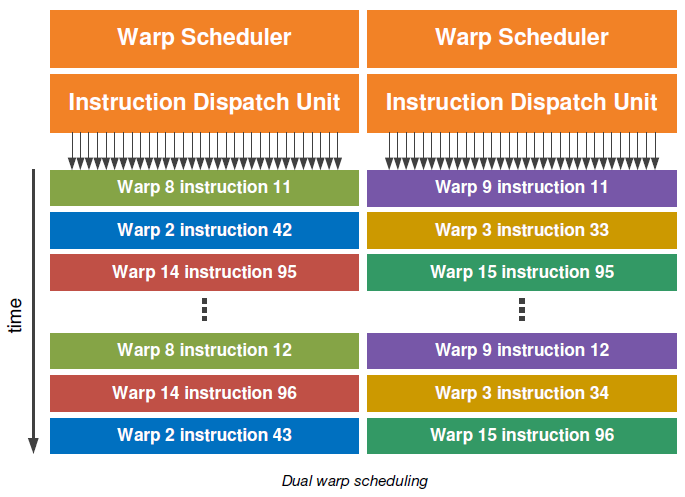
Powyższy podwojony scheduler Fermi, dzięki dwóm niezależnym i pracującym konkurencyjnie jednostkom, nie wymaga także sprawdzania zależności przesyłanego w jednym czasie strumienia instrukcji (dotyczy zarówno inst. stało- i zmiennoprzecinkowych, jak i wymieszanych z inst. zapisz, przechowaj, oraz funkcji specjalnych). Dzięki temu poszczególne wątki, bądź ich grupy, są znacznie efektywniej rozdzielane pomiędzy poszczególne jednostki wykonawcze. 
Zmniejszenie „korków” na liniach komunikacyjnych wewnątrz układu to zasługa optymalizacji zarówno dwupoziomowej pamięci podręcznej, jak i tej dedykowanej. Zwiększenie programowalności i wydajności tej struktury ma się przekładać na poprawioną efektywność GF100 w obliczeniach równoległych wykorzystujących aplikacje CUDA i model fizyki PhysX. W odróżnieniu od G80, G92, czy GT200, każdy blok SM dysponuje własną pamięcią podręczną o pojemności już nie 16KB, a 64KB (w zmiennej konfiguracji 48 + 16, albo 16 + 48 dla pamięci współdzielonej bądź L1).

Cały podsystem pamięci nosi nazwę Parallel DataCache i dotyczy zarówno pamięci podręcznej, globalnej, jak i współdzielonej. Zastosowanie aż tylu poziomów pamięci (w dodatku łatwo konfigurowalnej) podręcznej będzie mieć jednak swoje uzasadnienie. 
Niektóre mapy algorytmów wymagają - dla optymalnej prędkości przetwarzania całego wątku - umieszczenia ich raz w pamięci współdzielonej (shared memory cache), a innym razem w L1, bądź podzielnie w obu naraz. Lepsza konfigurowalność tego poziomu cache pozwala też na bardziej efektywne korzystanie z możliwości jego partycjonowania (48 + 16, bądź 16 + 48 KB).

Docelowa wydajność podsystemu pamięci współdzielonej w stosunku do układu GT200
W odróżnieniu od poziomu pierwszego L1, w pojemniejszej pamięci L2 (768KB) oprócz ścieżek do żądań dla LD/ST podtrzymywane są także adresy położenia tekstur w przestrzeni DRAM. Architektura Fermi, w odróżnieniu od GT200 (tylko odczyt), pozwala także na operacje zapisu do cache L2.

Ogólna wyższość przepływności pamięci podręcznych układu Fermi nad GT200 w PhysX
Funkcją znacznie przyspieszającą działania wątkowe oraz usprawniającą wymianę danych w pamięci cache są tzw. operacje atomowe (Fast Atomic Memory Operations). Dzięki nim konkurencyjne wątki nie mają możliwości wzajemnego blokowania już od momentu ich odczytu. Operacje atomowe są dziś szeroko stosowane w sortowaniu, redukcji oraz budowaniu (tworzeniu) struktur danych – modyfikacje na równoległych wątkach.
Zastosowany w układzie sześciokanałowy kontroler pamięci GDDR5, oprócz własnej korekcji EDC, ma także obsługę modułów ECC (Error Correction Code), a więc z dodatkowym bitem przeznaczonym dla korekcji błędów. Wykorzystanie takich pamięci może być przydatne np. w klastrach obliczeniowych (Compute Mode), gdzie konieczność uzyskania jak najwyższej precyzji jest jednym z nadrzędnych priorytetów.




